Network Architecture
All deep learning models in Visiopharm are so-called semantic segmentation networks, that utilize deep convolutional neural networks (CNNs). Most of the models use a VGG-style (Simonyan & Zisserman, 2014) encoder as backbone CNN. Here we cover U-Net (default), DeepLabv3+, FCN-8s, and a Comparison of U-net and DeepLabV3.
U-Net (Default)
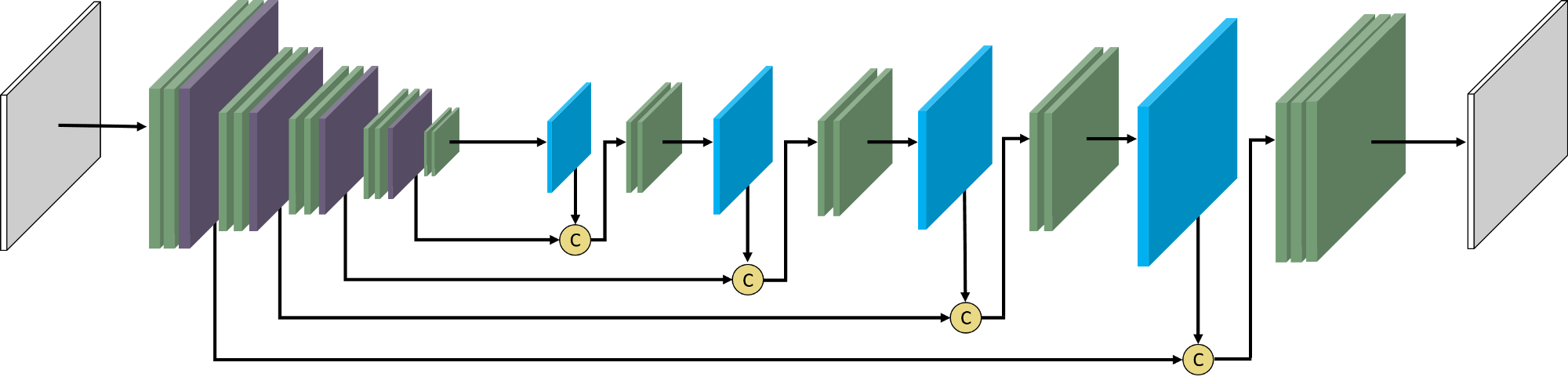
U-Net drops the last two layers of VGG in order to speed up the computation. The U-Net concatenates the information of the previous tensor and the up-sampling tensor rather that using element-wise addition to fusion the information. This is two advantages of the U-Net compared to the FCN network. The tensor will also get through two convolution layers to reinforce the intensity after each up-sampling operation. We generally recommend using the U-Net network architecture over the FCN-8s architecture. For more information about U-Net, see the original paper (Ronneberger, Fischer, & Brox 2015).
DeepLabv3+ (Requires GPU)
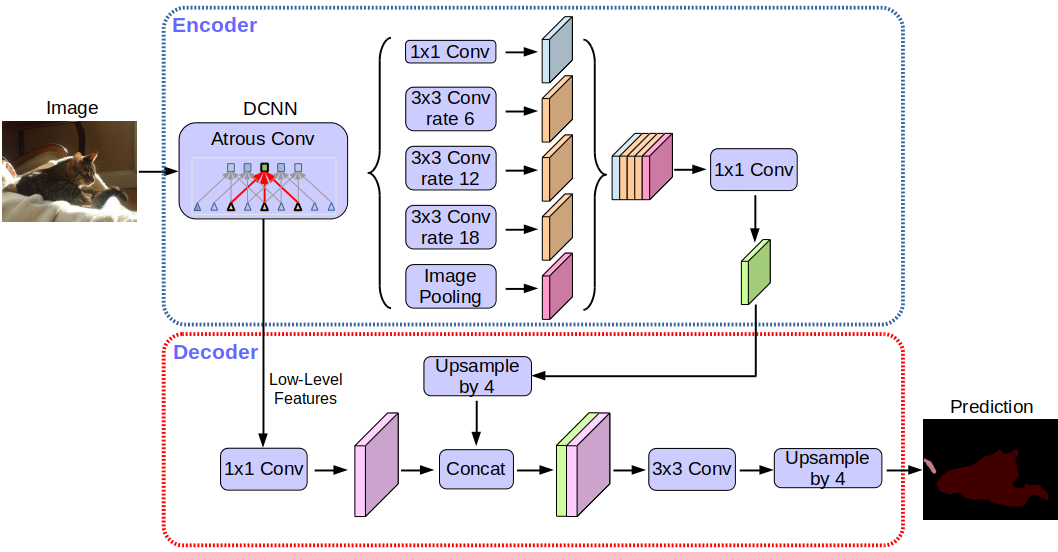
DeepLabv3+ use atrous spatial pyramid pooling (ASPP) module augmented with image-level feature to capture feature information on different scales. This means that instead of use step-wise upsampling blocks to incorporate features from different levels, this network only needs two upsampling steps, i.e. it is faster to train and analyze than e.g. the U-Net. All of this also means that the decoder module can refine the segmentation results along the object boundaries more precise. For more information on the DeepLabv3+ network architecture please refer to the original paper (Chen et al. 2018).
FCN-8s
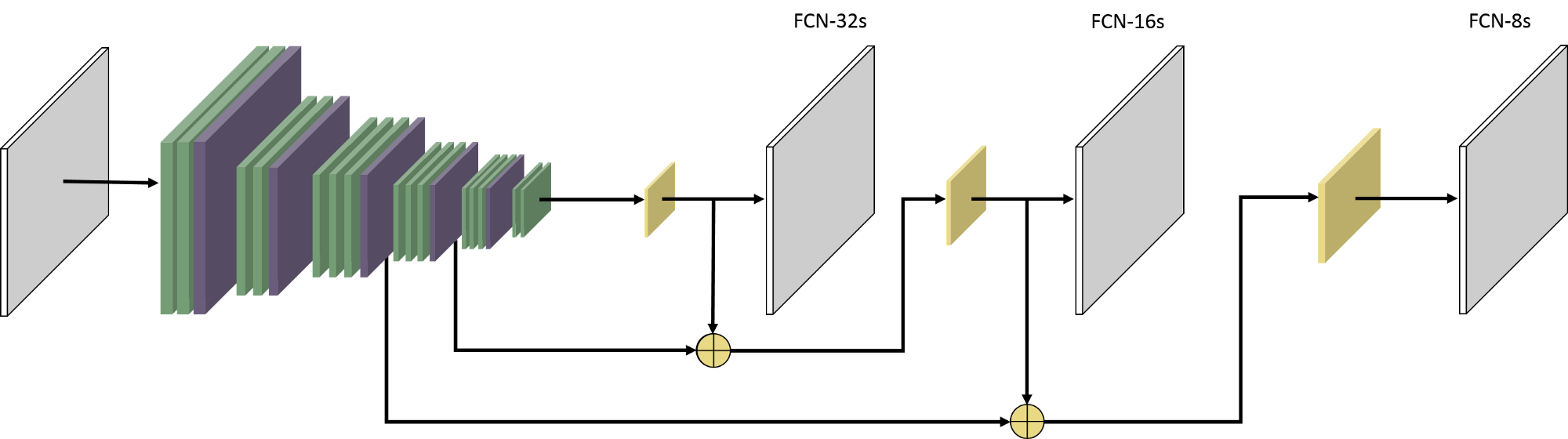
The FCN (fully convolutional network) originates from a desire to segment objects in pixels instead of just object recognition. It processes the image through the network and produces the course feature response map at the end, which will be up-sampled. The FCN-8s means that the result is shrank 8 times of the original image and it gets through two up-sampling layers and element-wise additions. For more information on FCN-8s network architecture, please refer to this paper (Long, Shelhamer, & Darrell 2015).
Comparison of U-net and DeepLabV3+
| U-net | DeepLabV3+ |
|---|---|
| Good at segmenting small structures (nuclei etc.) with high detail level. | Good at segmenting large, size-varying structures. More Context based. |
| Slower convergence and slower runtime (compared to DeepLabv3+). | Faster convergence and faster runtime (compared to U-net). |
| Default framework in VIS. Originally developed for medical image segmentation. | Segmentation results are smoother and more precise around the object boundaries (compared to U-Net). |
| Example application: Nuclei Detection. | Example application: Detection of Metastatic areas Tumor/stroma separation. |