K-means clustering
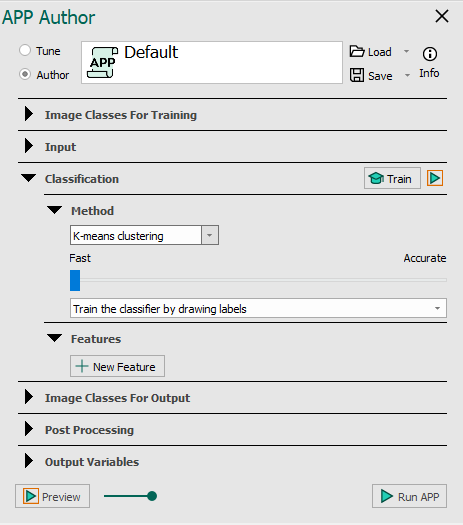
K-means Clustering is a very useful method to compensate for variation in Staining and Lighting throughout the dataset. To use K-Means clustering, the individual feature bands must be comparable (i.e. they must be approximately the same scale).
-
Slider - The slider in the K-means method is used to control the speed and accuracy ratio of the algorithm. Setting the slider to a fast setting will, as implied, speed up the classification. A high accuracy setting spreads affiliation of each pixel to more classes to increase the classification accuracy between classes.
-
Mode - K-means can be either supervised or unsupervised.
When used supervised the mode is set to Train the classifier by drawing labels, and K-means needs to be trained using training labels. To do this, there must be a label present for each class in the image (e.g. background, cytoplasm, nuclei).
When used unsupervised, a number of classes has to be specified. This number should correspond to how many classes that exist in the image, and the classifier will automatically separate the image pixel intensities into the number of classes given according to the K-means algorithm (eg. if unsupervised using 5 classes is selected, the image pixel intensities will be divided into 5 classes).
When ready, click Run APP to run the classification on the ROIs selected in the Regions To Analyze subsection in the Input section.